

About
Most people share, smart people sharrr.

Intro
This project is proof-of-concept on how to transfer large files over the internet asynchronously and in the most secure way possible, using zero-knowledge encryption.
All code is open source on Github.
Read the background story about this project in my blog.
Get in touch Bluesky or Mastodon.
Features
- End-to-end encrypted file transfer
- Parallel upload
- Support for extra large files (Technically there is no file size limit)
- One-time download link
- 7 day retention period (Download link expires and files are being deleted afterwards.)
- Files are stored in Switzerland
Fair use
Play fair - this is a non-commercial project that is meant for personal use only.
Tip
Downloading large files seems to work best in Firefox.
Technical details
The main idea is that, after the file has been encrypted and uploaded, only the recipient of the download link is ever able to download and access the decrypted data (Build the file). Even if all other systems besides the client's browser (Backend, Database, S3 Storage) would be compromised, it shouldn't be possible to decompile or reverse-engineer the original file. Apart from the end-to-end encryption, the file shall only be downloaded once (within a defined period of time).
Challenges
File encryption requires internal memory: A big challenge when it comes to big files is memory (RAM) limitations. If you wanted to encrypt/decrypt a file at once, you needed twice the file size reserved in memory. For huge files, this amount of memory is simply not available - especially on mobile phones. Another challenge is storing huge files in general. Most storage providers have a 5 GB limitation. And, finally, there are many challenges around security: How to design an architecture that keeps your data secure, even in case all the infrastructure gets compromised?
Implementation
The solution is to break down the files into chunks, and encrypt/decrypt them separately. Each chunk is saved individually to not only circumvent storage limitations but also to increase security. (From a storage perspective each chunk is just a bunch of binary data - it is not obvious which chunks make up a specific file.) Similar to the storage, the database only contains encrypted data. There is no way to reference database entries directly to files. Only the client with a valid link is able to connect all the dots and access the original file.
The following schema shows a simplified version of the implementation:
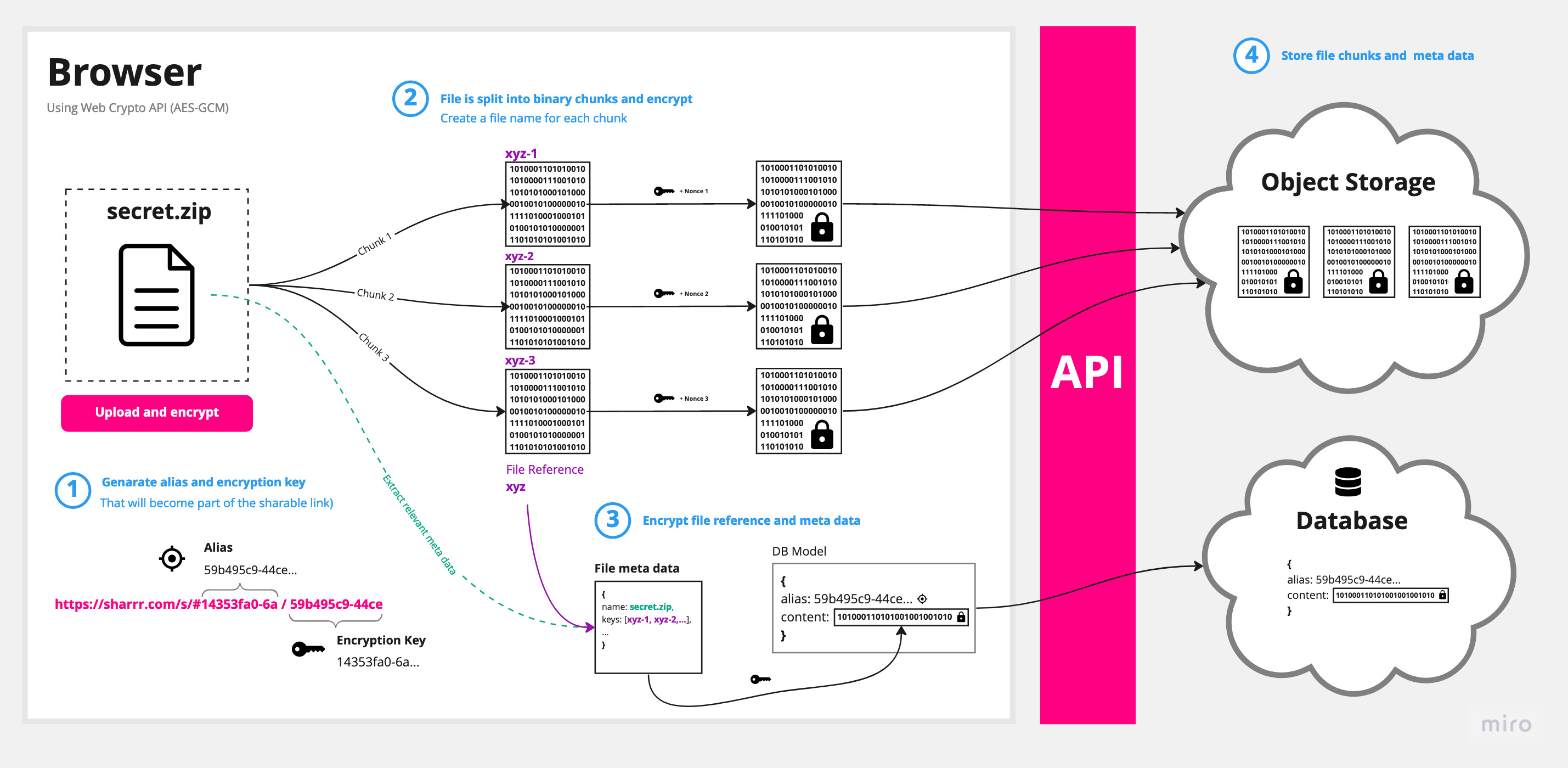
It is worth noting here that the alias and master key never leave the browser. Both strings will be added to the fragment identifier of the download link. This commonly referred to as the #hash or anchor part of the URL is never sent to the server. (You can check yourself in your browser's devtools: When you access a link, this information will not be sent as part of the request.)
Upload (Encryption)
Encrypting the file is the easier part: First, a file is split into smaller chunks. Those chunks then get encrypted separately and stored on S3. A reference to each chunk, together with a signature and a public key is afterwards stored in the database.
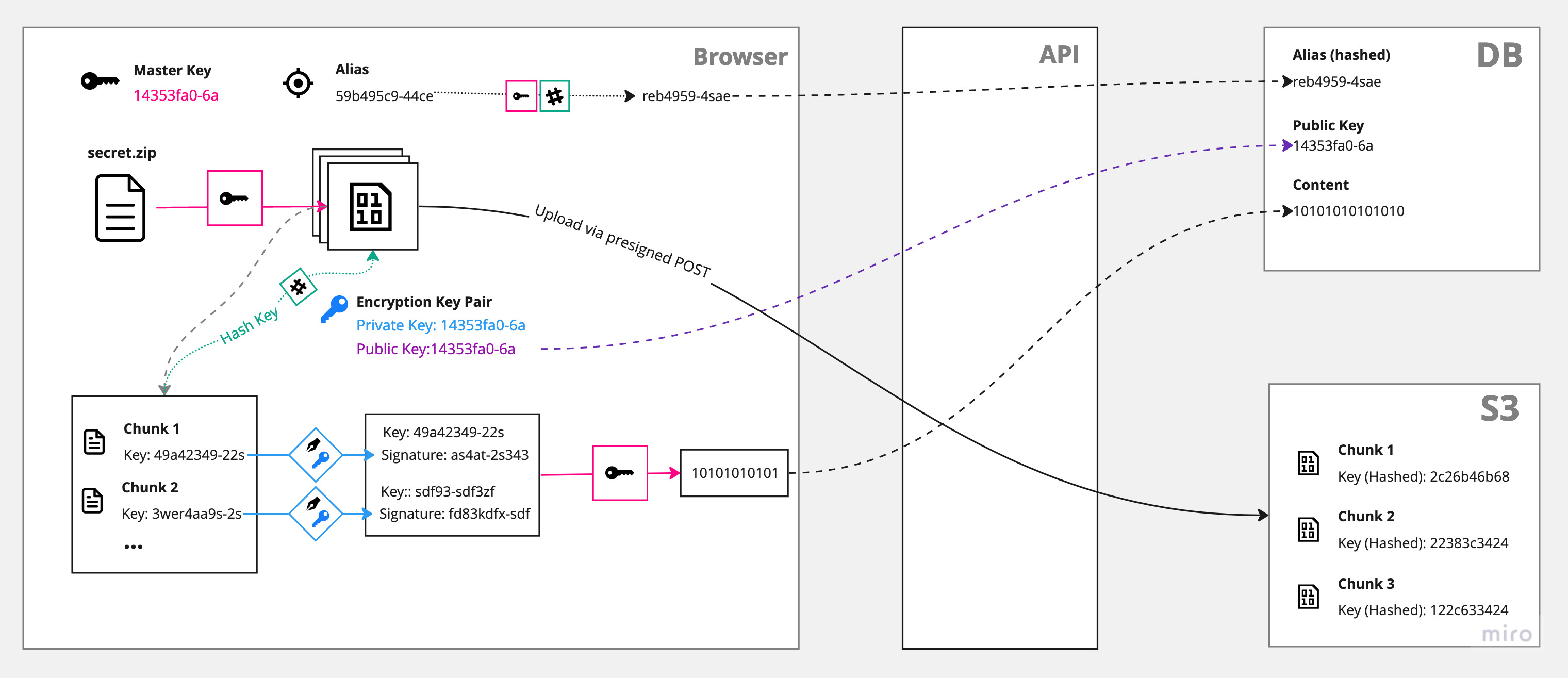
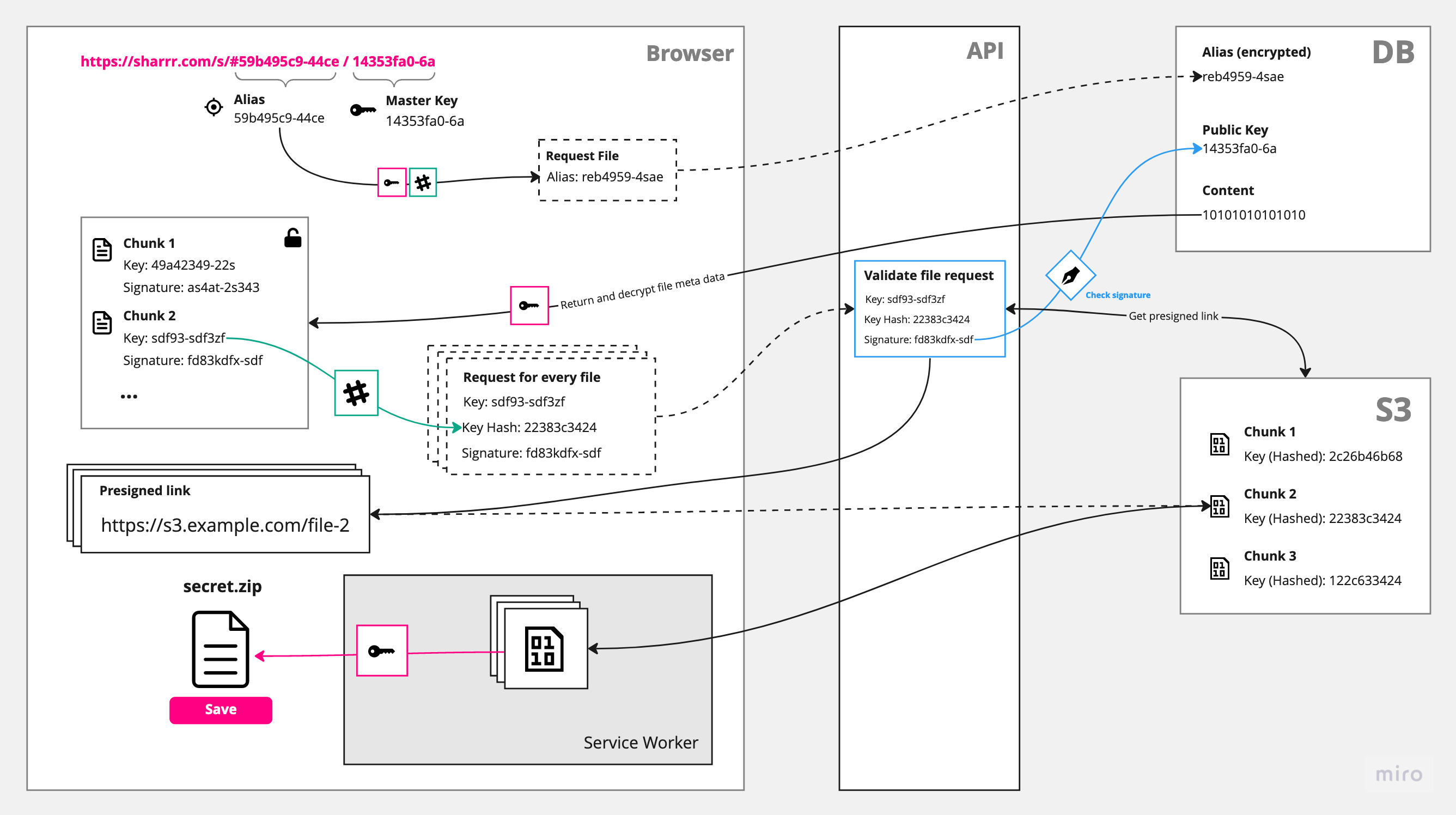
Download (Decryption)
The download and decryption is the tricky part. Not only do we need to make sure the client is allowed to request a certain file (solved with a cryptographic signature, see blue box), but also it is not possible to stream files directly into the download folder. We, therefore, need a service worker in between. If you want to learn more about how this works, I recommend this video or this blog post.
Cryptography
For encryption/decryption only built-in browser APIs are used, namely the Web Crypto API. As a side effect, this app won't run in legacy browsers or with older node versions. The following algorithms are being used:
- AES-GCM (Advanced Encryption Standard - Galois/Counter Mode) for symmetric encryption: This is used for the master key that encrypts/decrypts all file chunks and the data stored in the database.
- ECDSA (Elliptic Curve Digital Signature Algorithm) for asymmetric encryption: This is used to sign the file chunk keys in order to make sure the later download request is allowed to access this specific chunk file.
Resources
This project is heavily inspired by a great online community and amazing open-source projects:
- hat.sh - A client-side file encryption project
- Proton Drive security model explained (Blog)
- Firefox Send (Archived Repo)
- Thomas Konrad on end-to-end encryption (Video)
- MDN Docs about Web Crypto API